Chapter 2. Hardware Installation and Operating System Configuration
To set up the hardware configuration and install Red Hat Enterprise Linux, follow these steps:
Choose a cluster hardware configuration that meets the needs of applications and users; refer to Section 2.1 Choosing a Hardware Configuration.
Set up and connect the members and the optional console switch and network switch or hub; refer to Section 2.2 Setting Up the Members.
Install and configure Red Hat Enterprise Linux on the cluster members; refer to Section 2.3 Installing and Configuring Red Hat Enterprise Linux.
Set up the remaining cluster hardware components and connect them to the members; refer to Section 2.4 Setting Up and Connecting the Cluster Hardware.
After setting up the hardware configuration and installing Red Hat Enterprise Linux, install the cluster software.
 | Tip |
|---|---|
Refer to the Red Hat Hardware Compatibility List available at http://hardware.redhat.com/hcl/ for a list of compatible hardware. Perform a Quick Search for the term cluster to find results for power switch and shared storage hardware certified for or compatible with Red Hat Cluster Manager. For general system hardware compatibility searches, use manufacturer, brand, and/or model keywords to check for compatibility with Red Hat Enterprise Linux. |
2.1. Choosing a Hardware Configuration
The Red Hat Cluster Manager allows administrators to use commodity hardware to set up a cluster configuration that meets the performance, availability, and data integrity needs of applications and users. Cluster hardware ranges from low-cost minimum configurations that include only the components required for cluster operation, to high-end configurations that include redundant Ethernet channels, hardware RAID, and power switches.
Regardless of configuration, the use of high-quality hardware in a cluster is recommended, as hardware malfunction is a primary cause of system down time.
Although all cluster configurations provide availability, some configurations protect against every single point of failure. In addition, all cluster configurations provide data integrity, but some configurations protect data under every failure condition. Therefore, administrators must fully understand the needs of their computing environment and also the availability and data integrity features of different hardware configurations to choose the cluster hardware that meets the proper requirements.
When choosing a cluster hardware configuration, consider the following:
- Performance requirements of applications and users
Choose a hardware configuration that provides adequate memory, CPU, and I/O resources. Be sure that the configuration chosen can handle any future increases in workload as well.
- Cost restrictions
The hardware configuration chosen must meet budget requirements. For example, systems with multiple I/O ports usually cost more than low-end systems with fewer expansion capabilities.
- Availability requirements
If a computing environment requires the highest degree of availability, such as a production environment, then a cluster hardware configuration that protects against all single points of failure, including disk, storage interconnect, Ethernet channel, and power failures is recommended. Environments that can tolerate an interruption in availability, such as development environments, may not require as much protection. Refer to Section 2.4.3 Configuring UPS Systems and Section 2.4.4 Configuring Shared Disk Storagefor more information about using redundant hardware for high availability.
- Data integrity under all failure conditions requirement
Using power switches in a cluster configuration guarantees that service data is protected under every failure condition. These devices enable a member to power cycle another member before restarting its services during failover. Power switches protect against data corruption if an unresponsive (or hanging) member becomes responsive after its services have failed over and then issues I/O to a disk that is also receiving I/O from the other member.
In addition, if a quorum daemon fails on a member, the member is no longer able to monitor the shared cluster partitions. If you are not using power switches in the cluster, this error condition may result in services being run on more than one member, which can cause data corruption. Refer to Section 2.4.2 Configuring Power Switches for more information about the benefits of using power switches in a cluster. It is recommended that production environments use power switches or watchdog timers in the cluster configuration.
2.1.1. Shared Storage Requirements
The operation of the cluster depends on reliable, coordinated access to shared storage. In the event of hardware failure, it is desirable to be able to disconnect one member from the shared storage for repair without disrupting the other members. Shared storage is truly vital to the cluster configuration.
Testing has shown that it is difficult, if not impossible, to configure reliable multi-initiator parallel SCSI configurations at data rates above 80MB/sec using standard SCSI adapters. Further tests have shown that these configurations cannot support online repair because the bus does not work reliably when the HBA terminators are disabled, and external terminators are used. For these reasons, multi-initiator SCSI configurations using standard adapters are not supported. Either single-initiator SCSI bus adapters (connected to multi-ported storage) or Fibre Channel adapters are required.
The Red Hat Cluster Manager requires that all cluster members have simultaneous access to the shared storage. Certain host RAID adapters are capable of providing this type of access to shared RAID units. These products require extensive testing to ensure reliable operation, especially if the shared RAID units are based on parallel SCSI buses. These products typically do not allow for online repair of a failed member. Only host RAID adapters listed in the Red Hat Hardware Compatibility List are supported.
The use of software RAID, or software Logical Volume Management (LVM), is not supported on shared storage. This is because these products do not coordinate access from multiple hosts to shared storage. Software RAID or LVM may be used on non-shared storage on cluster members (for example, boot and system partitions, and other file systems which are not associated with any cluster services).
2.1.2. Minimum Hardware Requirements
A minimum hardware configuration includes only the hardware components that are required for cluster operation, as follows:
Two servers to run cluster services
Ethernet connection for sending heartbeat pings and for client network access
Shared disk storage for the shared cluster partitions and service data
The hardware components described in Table 2-1 can be used to set up a minimum cluster configuration. This configuration does not guarantee data integrity under all failure conditions, because it does not include power switches. Note that this is a sample configuration; it is possible to set up a minimum configuration using other hardware.
 | Warning |
|---|---|
The minimum cluster configuration is not a supported solution and should not be used in a production environment, as it does not guarantee data integrity under all failure conditions. |
| Hardware | Description |
|---|---|
| Two servers | Each member includes a network interface for client access and for Ethernet connections and a SCSI adapter (termination disabled) for the shared storage connection |
| Two network cables with RJ45 connectors | Network cables connect an Ethernet network interface on each member to the network for client access and heartbeat pings. |
| RAID storage enclosure | The RAID storage enclosure contains one controller with at least two host ports. |
| Two HD68 SCSI cables | Each cable connects one HBA to one port on the RAID controller, creating two single-initiator SCSI buses. |
Table 2-1. Example of Minimum Cluster Configuration
The minimum hardware configuration is the most cost-effective cluster configuration; however, it includes multiple points of failure. For example, if the RAID controller fails, then all cluster services become unavailable. When deploying the minimal hardware configuration, software watchdog timers should be configured as a data integrity provision. Refer to Section D.1.2.3 Configuring a Hardware Watchdog Timer for details.
To improve availability, protect against component failure, and guarantee data integrity under all failure conditions, the minimum configuration can be expanded, as described in Table 2-2.
| Problem | Solution |
|---|---|
| Disk failure | Hardware RAID to replicate data across multiple disks |
| RAID controller failure | Dual RAID controllers to provide redundant access to disk data |
| Heartbeat failure | Ethernet channel bonding and failover |
| Power source failure | Redundant uninterruptible power supply (UPS) systems |
| Data corruption under all failure conditions | Power switches or hardware-based watchdog timers |
Table 2-2. Improving Availability and Guaranteeing Data Integrity
A no single point of failure hardware configuration that guarantees data integrity under all failure conditions can include the following components:
At least two servers to run cluster services
Ethernet connection between each member for heartbeat pings and for client network access
Dual-controller RAID array to replicate shared partitions and service data
Power switches to enable each member to power-cycle the other members during the failover process
Ethernet interfaces configured to use channel bonding
At least two UPS systems for a highly-available source of power
The components described in Table 2-3 can be used to set up a no single point of failure cluster configuration that includes two single-initiator SCSI buses and power switches to guarantee data integrity under all failure conditions. Note that this is a sample configuration; it is possible to set up a no single point of failure configuration using other hardware.
| Hardware | Description | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Two servers (up to 8 supported) |
| ||||||||
| One network switch | A network switch enables the connection of multiple members to a network. | ||||||||
| One Cyclades terminal server | A terminal server allows for management of remote members from a central location. (A terminal server is not required for cluster operation.) | ||||||||
| Four network cables | Network cables connect the terminal server and a network interface on each member to the network switch. | ||||||||
| Two RJ45 to DB9 crossover cables | RJ45 to DB9 crossover cables connect a serial port on each member to the Cyclades terminal server. | ||||||||
| Two serial-attached power switches | Power switches enable each member to power-cycle the other member before restarting its services. The power cable for each member is connected to its own power switch. Note that serial-attach power switches are supported in two-member clusters only. | ||||||||
| Two null modem cables | Null modem cables connect a serial port on each member to the power switch that provides power to the other member. This connection enables each member to power-cycle the other member. | ||||||||
| FlashDisk RAID Disk Array with dual controllers | Dual RAID controllers protect against disk and controller failure. The RAID controllers provide simultaneous access to all the logical units on the host ports. | ||||||||
| Two HD68 SCSI cables | HD68 cables connect each host bus adapter to a RAID enclosure "in" port, creating two single-initiator SCSI buses. | ||||||||
| Two terminators | Terminators connected to each "out" port on the RAID enclosure terminate both single-initiator SCSI buses. | ||||||||
| Redundant UPS Systems | UPS systems provide a highly-available source of power. The power cables for the power switches and the RAID enclosure are connected to two UPS systems. |
Table 2-3. Example of a No Single Point of Failure Configuration
Figure 2-1 shows an example of a no single point of failure hardware configuration that includes the previously-described hardware, two single-initiator SCSI buses, and power switches to guarantee data integrity under all error conditions. A "T" enclosed in a circle represents a SCSI terminator.
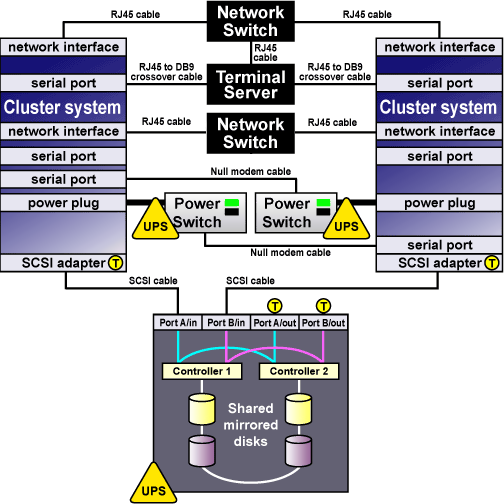
Cluster hardware configurations can also include other optional hardware components that are common in a computing environment. For example, a cluster can include a network switch or network hub, which enables the connection of the members to a network. A cluster may also include a console switch, which facilitates the management of multiple members and eliminates the need for separate monitors, mouses, and keyboards for each member.
One type of console switch is a terminal server, which enables connection to serial consoles and management of many members from one remote location. As a low-cost alternative, you can use a KVM (keyboard, video, and mouse) switch, which enables multiple members to share one keyboard, monitor, and mouse. A KVM is suitable for configurations in which access to a graphical user interface (GUI) to perform system management tasks is preferred.
When choosing a system, be sure that it provides the required PCI slots, network slots, and serial ports. For example, a no single point of failure configuration requires multiple bonded Ethernet ports. Refer to Section 2.2.1 Installing the Basic Cluster Hardware for more information.
2.1.3. Choosing the Type of Power Controller
The Red Hat Cluster Manager implementation consists of a generic power management layer and a set of device-specific modules which accommodate a range of power management types. When selecting the appropriate type of power controller to deploy in the cluster, it is important to recognize the implications of specific device types. The following describes the types of supported power switches followed by a summary table. For a more detailed description of the role a power switch plays to ensure data integrity, refer to Section 2.4.2 Configuring Power Switches.
Serial-attached and network-attached power switches are separate devices which enable one cluster member to power cycle another member. They resemble a power plug strip on which individual outlets can be turned on and off under software control through either a serial or network cable. Network-attached power switches differ from serial-attached in that they connect to cluster members via an Ethernet hub or switch, rather than direct connection to cluster members. A network-attached power switch can not be directly attached to a cluster member using a crossover cable, as the power switch would be unable to power cycle the other members.
Watchdog timers provide a means for failed members to remove themselves from the cluster prior to another member taking over its services, rather than allowing one cluster member to power cycle another. The normal operational mode for watchdog timers is that the cluster software must periodically reset a timer prior to its expiration. If the cluster software fails to reset the timer, the watchdog triggers under the assumption that the member may have hung or otherwise failed. The healthy cluster member allows a window of time to pass prior to concluding that another cluster member has failed (by default, this window is 12 seconds). The watchdog timer interval must be less than the duration of time for one cluster member to conclude that another has failed. In this manner, a healthy member can assume, prior to taking over services, that the failed cluster member has safely removed itself from the cluster (by rebooting) and is no longer a risk to data integrity. The underlying watchdog support is included in the core Linux kernel. Red Hat Cluster Manager utilizes these watchdog features via its standard APIs and configuration mechanism.
There are two types of watchdog timers: hardware-based and software-based. Hardware-based watchdog timers typically consist of system board components such as the Intel� i810 TCO chipset. This circuitry has a high degree of independence from the main system CPU. This independence is beneficial in failure scenarios of a true system hang, as in this case it pulls down the system's reset lead resulting in a system reboot. Some PCI expansion cards provide watchdog features.
Software-based watchdog timers do not have any dedicated hardware. The implementation is a kernel thread which is periodically run; if the timer duration has expired, the thread initiates a system reboot. The vulnerability of the software watchdog timer is that under certain failure scenarios, such as system hangs while interrupts are blocked, the kernel thread is not called. As a result, in such conditions it cannot be definitively depended on for data integrity. This can cause the healthy cluster member to take over services for a hung member which could cause data corruption under certain scenarios.
Finally, administrators can choose not to employ a power controller at all. When a power controller is not in use, no provision exists for a cluster member to power cycle a failed member. Similarly, the failed member cannot be guaranteed to reboot itself under all failure conditions.
 | Important |
|---|---|
Use of a power controller is strongly recommended as part of a production cluster environment. Configuration of a cluster without a power controller is not supported. |
Ultimately, the right type of power controller deployed in a cluster environment depends on the data integrity requirements weighed against the cost and availability of external power switches.
Table 2-4 summarizes the types of supported power management modules and discusses their advantages and disadvantages individually.
| Type | Notes | Pros | Cons |
|---|---|---|---|
| Serial-attached power switches (supported for two-member clusters only) | Two serial attached power controllers are used in a cluster (one per member) | Affords strong data integrity guarantees — the power controller itself is not a single point of failure as there are two in a cluster | Requires purchase of power controller hardware and cables; consumes serial ports; can only be used in two-member cluster |
| Network-attached power switches | A single network attached power controller is required per cluster (depending on the number of members); however, up to three are supported for each cluster member | Affords strong data integrity guarantees and can be used in clusters with more than two members | Requires purchase of power controller hardware — the power controller itself can become a single point of failure (although they are typically very reliable devices) |
| Hardware Watchdog Timer | Affords strong data integrity guarantees | Obviates the need to purchase external power controller hardware | Not all systems include supported watchdog hardware |
| Software Watchdog Timer | Offers acceptable data integrity provisions | Obviates the need to purchase external power controller hardware; works on any system | Under some failure scenarios, the software watchdog is not operational, opening a small vulnerability window |
| No power controller | No power controller function is in use | Obviates the need to purchase external power controller hardware; works on any system | Vulnerable to data corruption under certain failure scenarios |
Table 2-4. Power Switches
2.1.4. Cluster Hardware Components
Use the following tables to identify the hardware components required for the cluster configuration.
Table 2-5 includes the hardware required for the cluster members.
| Hardware | Quantity | Description | Required |
|---|---|---|---|
| Cluster members | eight (maximum supported) | Each member must provide enough PCI slots, network slots, and serial ports for the cluster hardware configuration. Because disk devices must have the same name on each member, it is recommended that the members have symmetric I/O subsystems. It is also recommended that the processor speed and amount of system memory be adequate for the processes run on the cluster members. Consult the Red Hat Enterprise Linux 3 Release Notes for specifics. Refer to Section 2.2.1 Installing the Basic Cluster Hardware for more information. | Yes |
Table 2-5. Cluster Member Hardware
Table 2-6 includes several different types of power switches.
A single cluster requires only one type of power switch.
| Hardware | Quantity | Description | Required |
|---|---|---|---|
| Serial power switches | Two | In a two-member cluster, use serial power switches to enable each cluster member to power-cycle the other member. Refer to Section 2.4.2 Configuring Power Switches for more information. Note, cluster members are configured with either serial power switches (supported for two-member clusters only) or network-attached power switches, but not both. | Strongly recommended for data integrity under all failure conditions |
| Null modem cable | Two | Null modem cables connect a serial port on a cluster member to a serial power switch. This enables each member to power-cycle the other member. Some power switches may require different cables. | Only if using serial power switches |
| Mounting bracket | One | Some power switches support rack mount configurations and require a separate mounting bracket. | Only for rack mounting power switches |
| Network power switch | One (depends on member count) | Network-attached power switches enable each cluster member to power cycle all others. Refer to Section 2.4.2 Configuring Power Switches for more information. | Strongly recommended for data integrity under all failure conditions |
| Watchdog Timer | One per member | Watchdog timers cause a failed cluster member to remove itself from a cluster prior to a healthy member taking over its services. Refer to Section 2.4.2 Configuring Power Switches for more information. | Recommended for data integrity on systems which provide integrated watchdog hardware |
Table 2-6. Power Switch Hardware Table
Table 2-8 through Table 2-10 show a variety of hardware components for an administrator to choose from. An individual cluster does not require all of the components listed in these tables.
| Hardware | Quantity | Description | Required |
|---|---|---|---|
| Network interface | One for each network connection | Each network connection requires a network interface installed in a member. | Yes |
| Network switch or hub | One | A network switch or hub allows connection of multiple members to a network. | No |
| Network cable | One for each network interface | A conventional network cable, such as a cable with an RJ45 connector, connects each network interface to a network switch or a network hub. | Yes |
Table 2-7. Network Hardware Table
| Hardware | Quantity | Description | Required | ||||
|---|---|---|---|---|---|---|---|
| Host bus adapter | One per member |
| Yes | ||||
| External disk storage enclosure | At least one |
| Yes | ||||
| SCSI cable | One per member | SCSI cables with 68 pins connect each host bus adapter to a storage enclosure port. Cables have either HD68 or VHDCI connectors. Cables vary based on adapter type. | Only for parallel SCSI configurations | ||||
| SCSI terminator | As required by hardware configuration | For a RAID storage enclosure that uses "out" ports (such as FlashDisk RAID Disk Array) and is connected to single-initiator SCSI buses, connect terminators to the "out" ports to terminate the buses. | Only for parallel SCSI configurations and only as necessary for termination | ||||
| Fibre Channel hub or switch | One or two | A Fibre Channel hub or switch may be required. | Only for some Fibre Channel configurations | ||||
| Fibre Channel cable | As required by hardware configuration | A Fibre Channel cable connects a host bus adapter to a storage enclosure port, a Fibre Channel hub, or a Fibre Channel switch. If a hub or switch is used, additional cables are needed to connect the hub or switch to the storage adapter ports. | Only for Fibre Channel configurations |
Table 2-8. Shared Disk Storage Hardware Table
| Hardware | Quantity | Description | Required |
|---|---|---|---|
| Network interface | Two for each member | Each Ethernet connection requires a network interface card installed on all cluster members. | No |
| Network crossover cable | One for each channel | A network crossover cable connects a network interface on one member to a network interface on other cluster members, creating an Ethernet connection for communicating heartbeat. | Only for a redundant Ethernet connection (use of channel-bonded Ethernet connection is preferred) |
Table 2-9. Point-To-Point Ethernet Connection Hardware Table
| Hardware | Quantity | Description | Required |
|---|---|---|---|
| UPS system | One or more | Uninterruptible power supply (UPS) systems protect against downtime if a power outage occurs. UPS systems are highly recommended for cluster operation. Connect the power cables for the shared storage enclosure and both power switches to redundant UPS systems. Note, a UPS system must be able to provide voltage for an adequate period of time, and should be connected to its own power circuit. | Strongly recommended for availability |
Table 2-10. UPS System Hardware Table
| Hardware | Quantity | Description | Required |
|---|---|---|---|
| Terminal server | One | A terminal server enables you to manage many members from one remote location. | No |
| KVM | One | A KVM enables multiple members to share one keyboard, monitor, and mouse. Cables for connecting members to the switch depend on the type of KVM. | No |
Table 2-11. Console Switch Hardware Table