2. Cluster Features
A cluster includes the following features:
No-single-point-of-failure hardware configuration
Clusters can include a dual-controller RAID array, multiple network channels, and redundant uninterruptible power supply (UPS) systems to ensure that no single failure results in application down time or loss of data.
Alternately, a low-cost cluster can be set up to provide less availability than a no-single-point-of-failure cluster. For example, you can set up a cluster with a single-controller RAID array and only a single Ethernet channel. channel.

Note Certain low-cost alternatives, such as software RAID and multi-initiator parallel SCSI, are not compatible or appropriate for use on the shared cluster storage. Refer to Section 1.1 Choosing a Hardware Configuration, for more information.
Service configuration framework
Clusters allow you to easily configure individual services to make data and applications highly available. To create a service, you specify the resources used in the service and properties for the service, including the service name, application start, stop, and status script, disk partitions, mount points, and the cluster members on which you prefer the service to run. After you add a service, the cluster management software stores the information in a cluster configuration file on shared storage, where the configuration data can be accessed by all cluster members.
The cluster provides an easy-to-use framework for database applications. For example, a database service serves highly-available data to a database application. The application running on a cluster member provides network access to database client systems, such as Web servers. If the service fails over to another member, the application can still access the shared database data. A network-accessible database service is usually assigned an IP address, which is failed over along with the service to maintain transparent access for clients.
The cluster service framework can be easily extended to other applications, as well.
Failover domains
By assigning a service to a restricted failover domain, you can limit the members that are eligible to run a service in the event of a failover. (A service that is assigned to a restricted failover domain cannot be started on a cluster member that is not included in that failover domain.) You can order the members in a failover domain by preference to ensure that a particular member runs the service (as long as that member is active). If a service is assigned to an unrestricted failover domain, the service starts on any available cluster member (if none of the members of the failover domain are available).
Data integrity assurance
To ensure data integrity, only one member can run a service and access service data at one time. The use of power switches in the cluster hardware configuration enables a member to power-cycle another member before restarting that member's services during the failover process. This prevents any two systems from simultaneously accessing the same data and corrupting it. Although not required, it is recommended that power switches are used to guarantee data integrity under all failure conditions. Watchdog timers are an optional variety of power control to ensure correct operation of service failover.
Cluster administration user interface
The cluster administration interface facilitiates management tasks such as: creating, starting, and stopping services; relocating services from one member to another; modifying the cluster configuration (to add or remove services or resources); and monitoring the cluster members and services.
Ethernet channel bonding
To monitor the health of the other members, each member monitors the health of the remote power switch, if any, and issues heartbeat pings over network channels. With Ethernet channel bonding, multiple Ethernet interfaces are configured to behave as one, reducing the risk of a single-point-of-failure in the typical switched Ethernet connection between systems.
Shared storage for quorum information
Shared state information includes whether the member is active. Service state information includes whether the service is running and which member is running the service. Each member checks to ensure that the status of the other members is up to date.
In a two-member cluster, each member periodically writes a timestamp and cluster state information to two shared cluster partitions located on shared disk storage. To ensure correct cluster operation, if a member is unable to write to both the primary and shadow shared cluster partitions at startup time, it is not allowed to join the cluster. In addition, if a member is not updating its timestamp, and if heartbeats to the system fail, the member is removed from the cluster.
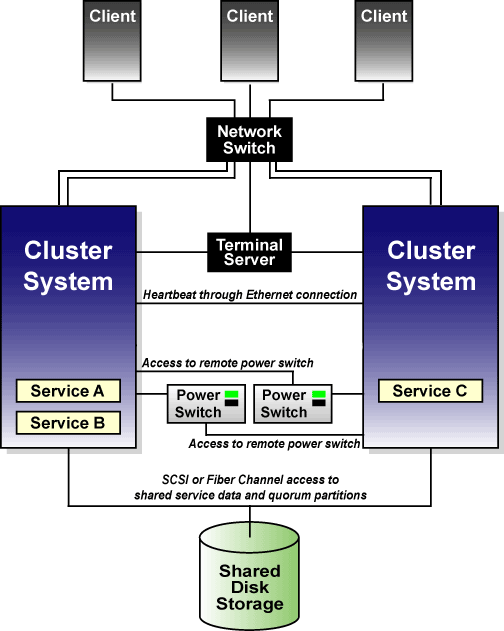
Figure 2 shows how members communicate in a cluster configuration. Note that the terminal server used to access system consoles via serial ports is not a required cluster component.
Service failover capability
If a hardware or software failure occurs, the cluster takes the appropriate action to maintain application availability and data integrity. For example, if a member completely fails, another member (in the associated failover domain, if used, or in the cluster) restarts its services. Services already running on this member are not disrupted.
When the failed member reboots and is able to write to the shared cluster partitions, it can rejoin the cluster and run services. Depending on how the services are configured, the cluster can re-balance the services among the members.
Manual service relocation capability
In addition to automatic service failover, a cluster allows you to cleanly stop services on one member and restart them on another member. You can perform planned maintenance on a member system while continuing to provide application and data availability.
Event logging facility
To ensure that problems are detected and resolved before they affect service availability, the cluster daemons log messages by using the conventional Linux syslog subsystem. You can customize the severity level of the logged messages.
Application monitoring
The infrastructure in a cluster can optionally monitor the state and health of an application. In this manner, should an application-specific failure occur, the cluster automatically restarts the application. In response to the application failure, the application attempts to be restarted on the member it was initially running on; failing that, it restarts on another cluster member. You can specify which members are eligible to run a service by assigning a failover domain to the service.